Peptide bonds are the chemical links that let amino acids connect into peptides and proteins. If you work with peptides in a laboratory setting—whether for assay development, receptor binding studies, structural work, or analytical method validation—understanding what a peptide bond is (and what it is not) helps you interpret sequences, predict behaviour, and communicate results clearly.
This guide explains peptide bonds in straightforward terms: how they form, how peptide chains are written and named, and why this particular bond has distinctive properties that shape peptide structure in research applications.
Where peptide bonds fit: amino acids, peptides, and proteins
A peptide bond only makes sense in context: it joins amino acids into a chain. If you want a broader introduction first, see What are peptides? and Amino acids explained.
In brief:
- Amino acids are small molecules with (at minimum) an amino group and a carboxyl group, plus a side chain (the “R group”) that varies between amino acids.
- Peptides are short chains of amino acids (often defined operationally in research by size and use-case rather than a strict cutoff).
- Proteins are longer amino-acid chains that often fold into complex three-dimensional structures and may form multi-subunit assemblies.
The repeating “backbone” of a peptide or protein is created by peptide bonds. The side chains hang off this backbone and strongly influence solubility, charge, binding, and folding—properties routinely measured in laboratory experiments.
What is a peptide bond?
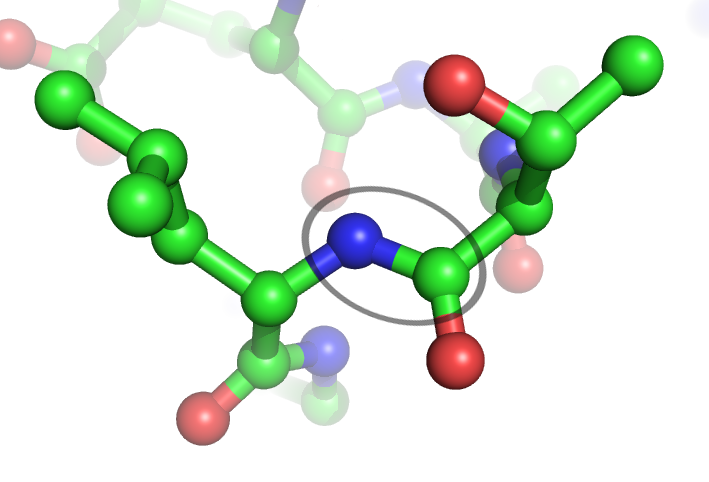
A peptide bond is a covalent bond that links two amino acids together. Specifically, it connects the carbonyl carbon (C=O) of one amino acid’s carboxyl group to the nitrogen (N–H) of the next amino acid’s amino group.
In chemical terms, this linkage is an amide bond. In biochemistry, when that amide bond connects amino acids in a chain, we commonly call it a peptide bond.
Once formed, peptide bonds create the repeating backbone pattern seen in peptides and proteins:
- …–N–Cα–C(=O)–N–Cα–C(=O)–…
Even without memorising the exact atoms, it helps to know that a peptide chain is not a random assortment of bonds. It is a regular backbone with predictable geometry, and that predictability is a major reason peptides and proteins can be analysed systematically in research (for example, by mass spectrometry and chromatography).
How peptide bonds form (the condensation idea)
Peptide bonds form through a condensation reaction (also called a dehydration reaction). The carboxyl group of one amino acid reacts with the amino group of another, and a molecule of water is released as the bond forms.
Conceptually, you can think of it like this:
- The first amino acid contributes the carbonyl (C=O) part.
- The second amino acid contributes the nitrogen (N) part.
- Water is eliminated in the process, leaving a stable covalent link.
In living systems, enzymes catalyse peptide bond formation during translation. In laboratory and industrial contexts, peptides can be assembled by controlled synthetic chemistry. If you’re interested in how peptide chains are built at a high level (without step-by-step protocols), see Peptide synthesis overview.
A quick example: joining two amino acids
Imagine joining glycine and alanine into a dipeptide. The carboxyl group of glycine links to the amino group of alanine, producing the dipeptide glycylalanine (often written Gly–Ala). The reverse order, Ala–Gly, is a different molecule with different properties because the termini are different.
Why peptides are written from N-terminus to C-terminus
Peptide sequences are written from the N-terminus to the C-terminus by convention. This standardises how sequences are described across publications, databases, and laboratory documentation.
- N-terminus: the end with a free (unlinked) amino group.
- C-terminus: the end with a free (unlinked) carboxyl group.
When you see a sequence like H–Ala–Gly–Ser–OH (sometimes simplified to Ala–Gly–Ser), it means alanine is at the N-terminus and serine is at the C-terminus. In research settings, consistent directionality matters for:
- Communicating identity: two sequences with the same amino acids but reversed order are not the same compound.
- Interpreting modifications: labels, tags, acetylation/amidation, and other terminal changes are defined relative to N- or C-termini.
- Mapping fragmentation data: mass spectrometry interpretations often reference sequence direction when assigning ions.
How peptide bonds are named and how peptides are named
Naming can sound more complicated than it is. There are two closely related ideas: naming the bond itself, and naming the peptide produced.
Peptide bond vs amide bond
In organic chemistry, an amide bond is the general term for a carbonyl carbon bonded to a nitrogen. In biochemistry, when that amide bond connects amino acids in a peptide chain, it’s commonly called a peptide bond. So, the terminology depends on context rather than on a different type of covalent linkage.
Using “-yl” forms inside peptide names
When amino acids are part of a chain (i.e., not at the C-terminus), their names often take an “-yl” form. For example:
- Glycine becomes glycyl (Gly–)
- Alanine becomes alanyl (Ala–)
- Valine becomes valyl (Val–)
In a dipeptide, the N-terminal residue typically takes the “-yl” form, while the C-terminal residue keeps the standard amino-acid name. For example:
- Gly–Ala can be called glycylalanine
- Ala–Gly can be called alanylglycine
In practice, laboratory work often uses one-letter or three-letter codes (e.g., Gly–Ala or GA) because they are unambiguous and easy to cross-reference with analytical data and ordering information.
Are peptide bonds strong? What breaks them?
Peptide bonds are generally strong covalent bonds, which is one reason peptides and proteins can be stable enough for purification, storage, and experimental handling. However, “strong” does not mean unbreakable. Peptide bonds can be cleaved under particular conditions, including:
- Enzymatic hydrolysis: proteases cleave peptide bonds with high specificity (commonly used in protein characterisation workflows).
- Chemical hydrolysis: strong acid or base conditions can promote cleavage (typically used in controlled analytical or preparative contexts, not as routine handling).
- Stress conditions: elevated temperature, extreme pH, or long incubation times can increase the likelihood of degradation pathways, depending on sequence and formulation.
In research, knowing that peptide bonds can be selectively cleaved is useful for designing experiments that map sequences, identify modifications, or validate identity through predictable fragments.
Why peptide bonds don’t rotate freely (and why that matters)
Many single bonds can rotate relatively freely. The peptide bond is different because it has partial double-bond character due to resonance (electron delocalisation) between the carbonyl group and the amide nitrogen.
This resonance leads to two practical consequences:
- Planarity: atoms around the peptide bond tend to lie in a plane.
- Restricted rotation: rotation around the C–N bond is limited compared with typical single bonds.
Instead of rotating freely at the peptide bond itself, peptide chains mainly adopt different shapes by rotating around the bonds adjacent to the alpha carbon (often described by backbone torsion angles). This is a foundational reason why peptides and proteins form recognisable secondary structures such as helices and sheets.
For a broader connection between peptide bonds and folding, see Protein structure (primary, secondary, tertiary).
Cis vs trans configuration
Because the peptide bond is planar, it also has a geometric arrangement often described as cis or trans. Most peptide bonds in proteins are in the trans configuration because it reduces steric clashes between side chains. An important exception involves residues like proline, where cis forms can be more common than in other contexts and can influence folding kinetics and conformational populations in experiments.
Why peptide bonds matter in laboratory research
Even if your work is not “about” peptide chemistry, peptide bonds influence many observable properties that researchers measure. Here are several ways peptide bonds show up in real laboratory workflows.
1) They define the primary structure you order, record, and verify
The sequence of amino acids—and therefore the pattern of peptide bonds—defines a peptide’s primary structure. Analytical confirmation (for example by LC-MS) typically relies on the expected mass and fragmentation behaviour of that covalent backbone.
Quality control concepts such as purity, identity, and related substances are central when using research peptides. For an overview of common characterisation approaches, see Peptide purity and analytical methods.
2) They influence folding, flexibility, and conformational ensembles
Because peptide bonds are relatively rigid, peptide backbones do not behave like unconstrained chains. Instead, they populate a set of conformations shaped by backbone geometry, side-chain interactions, solvent, and temperature. This matters for experiments such as:
- Binding studies, where conformation can affect interaction profiles.
- Spectroscopy (e.g., CD), where secondary structure signatures depend on backbone organisation.
- Chromatography, where conformation can subtly influence retention in some conditions.
3) They create predictable sites for controlled cleavage
Proteases and other cleavage strategies target peptide bonds in sequence-dependent ways. In protein research, controlled digestion patterns can help map domains, confirm identity, or support structural analysis. The key point is that the peptide bond is both stable and, under the right conditions, addressable with specificity.
4) They affect how modifications are described
Many research peptides include terminal modifications or internal substitutions. Clear understanding of the peptide bond and termini helps avoid ambiguity when documenting compounds. For example:
- N-terminal modifications occur at the amino end before the first peptide bond of the chain.
- C-terminal modifications occur at the carboxyl end after the last peptide bond of the chain.
- Backbone modifications (less common) alter the amide linkage itself and can have major effects on stability and conformation.
Common misconceptions about peptide bonds
“Peptide bonds are weak because peptides can degrade”
Degradation can happen, but it does not mean the peptide bond is inherently weak. Peptide stability depends on conditions and sequence context. Many degradation pathways involve specific residues, terminal chemistry, oxidation, deamidation, or aggregation rather than spontaneous peptide bond cleavage under mild conditions.
“All bonds in a peptide rotate the same way”
The peptide bond is special due to resonance and planarity. The backbone’s flexibility arises primarily from rotations around neighbouring bonds, not free rotation through the amide linkage.
“If two peptides have the same composition, they’re identical”
Composition (counts of each amino acid) is not enough. Sequence order and termini define different peptide bonds in different positions, leading to different molecules with different analytical and functional properties in research assays.
FAQ: peptide bonds
What is a peptide bond in simple terms?
A peptide bond is the covalent link that joins two amino acids together, forming the backbone of a peptide or protein chain.
Is a peptide bond the same as an amide bond?
Yes. In biochemistry, a peptide bond is an amide bond specifically formed between amino acids (the C=O group of one and the N–H group of another).
How do peptide bonds form?
They form via a condensation reaction where the carboxyl group of one amino acid reacts with the amino group of another, releasing a molecule of water.
Why are peptide chains written from N-terminus to C-terminus?
By convention, sequences are written from the end with the free amino group (N-terminus) to the end with the free carboxyl group (C-terminus), which standardises how peptides are described.
Are peptide bonds strong or weak?
Peptide bonds are generally strong covalent bonds, though they can be broken under particular chemical conditions or by enzymes.
Do peptide bonds rotate freely?
Not much. Due to electron sharing (resonance), the peptide bond has partial double-bond character, making that region relatively rigid compared with nearby bonds.
Key takeaways
- A peptide bond is an amide linkage connecting the carboxyl group of one amino acid to the amino group of the next.
- Peptide bonds form through a condensation reaction (water is released as the bond forms).
- Sequences are written N-terminus → C-terminus, and order matters because it defines a different molecule.
- Resonance gives the peptide bond partial double-bond character, making it relatively rigid and helping shape peptide and protein structure.
- In laboratory research, peptide bonds underpin sequence identity, structural behaviour, analytical verification, and controlled cleavage strategies.
For readers building a broader foundation, the following resources may help connect peptide bonds to the bigger picture of research peptides: What are peptides?, Amino acids explained, Protein structure (primary, secondary, tertiary), Peptide synthesis overview, and Peptide purity and analytical methods.